You might not know it, but machine learning already plays a part in your everyday life. When you speak to your phone (via Cortana, Siri or Google Now) and it fetches information, or you type in the Google search box and it predicts what you are looking for before you finish, you are doing something that has only been made possible by machine learning.

However, this is just the beginning: with companies such as Google, Microsoft and Facebook spending millions on research into advanced neural networks and deep machine learning, computers are set to get smarter still.
But deep learning isn’t about self-aware machines taking over the world. This is a story about how ingenious algorithms and code are giving computers the ability to do things we never previously thought possible.
How do computers learn?

Machine learning and deep learning have grown from the same roots within computer science, using many of the same concepts and techniques. Simply put, machine learning is an offshoot of artificial intelligence that enables a system to acquire knowledge through a supervised learning experience.
It’s a straightforward enough process, in theory: a human being provides data for analysis, and then gives error-correcting feedback that enables the system to improve itself. Depending upon the patterns in the data it’s exposed to, and which of those it recognises, the system will adjust its actions accordingly. It’s this ability to self-develop without the need for explicit programming, but rather to change and adapt when exposed to new data, that makes machine learning such a powerful tool.
However, what makes deep learning even more valuable is that it does so without, or with much less, human supervision. David Wood, co-founder of Symbian and now a “futurist” at Delta Wisdom, explains the difference using the example of face recognition.
“Recognising a face involves recognition of various sub-structures, known as features, such as eyes, the chin, nostrils, cheek dimples and so on. Eyes in turn are broken down into pupils, iris, and cornea. Standard machine learning requires these features to be pointed out to the computer, as so-called supervised learning.” In other words, the system has to learn to recognise nostrils, and then noses, before it’s really good at recognising faces.
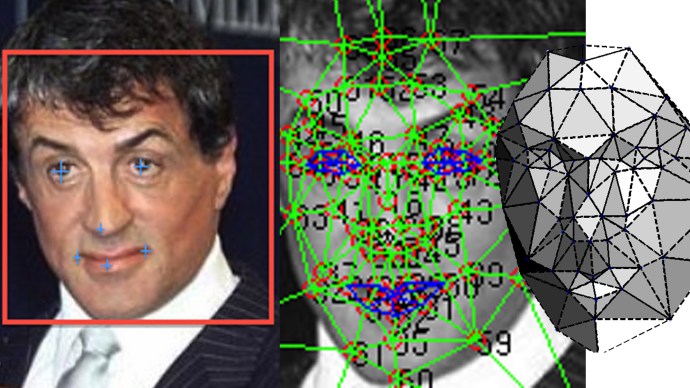
Image: FAIR DeepFace facial recognition techniques
Deep learning takes this concept a step further. “For deep learning, the software is able to reach its own conclusions about layers of intermediate functions that need to be identified. This is known as unsupervised learning. Throw in the fact that you need many layers for it to work properly, and you get the ‘deep’ bit.”
It’s this ability to learn and adapt to data that is allowing computers to do things that were never thought possible. Alexandre Dalyac, founder of Tractable, a company implementing deep learning into its real world solutions, believes that deep learning is set to change the face of computing. “It is important for the future of information technology because it is making tasks that were impossible to solve with IT possible to solve with IT.” As you’d imagine, though, Tractable is far from the only company which is keen to explore the frontiers of smart machines.
Deep learning, deep pockets
This is an area that has been attracting big investment. Last year, Google paid a reputed $400 million for London-based AI outfit DeepMind, a specialist in deep learning research. Peter Lee, head of Microsoft Research, went on record as stating that a “world-class deep learning expert” can command a seven-figure salary – these computer whisperers are the Premier League football stars of the programming world.

Image: Peter Lee, Corporate VP and Head of Microsoft Research
But not all the costs involved in such research are on an upwards curve: after all, it’s the dwindling price of computing power that has given deep learning the boost it needed to become a viable commercial reality. Serious computational power remains a necessity, but courtesy of the cloud, distributed computing and the application of graphic processing units (GPUs) to power the neural networks behind deep learning projects (Nvidia is an increasingly potent figure in the deep learning field as a direct result), the field is now accessible to companies with sizable, but not limitless, budgets.
The other part of the formula is data, the biggest data you can get your hands on – this is the key element required in order for these thinking computers to actually learn anything. When you look at some of the names causing the biggest stir commercially, such as Google, it’s hardly a surprise given the sheer amount of data they have access to. For deep learning experts in academic fields, the company’s vast repositories of information are a huge attraction.
Who’s winning the learning war?
“There’s a good reason why Google remains at the forefront of the deep learning revolution: data, and lots of it.”
So who is making the big moves in AI? Although Apple has recently been on a hiring mission, seeking 80-plus AI experts to help make Siri smarter than Google Now or Microsoft’s Cortana, it’s still playing catch-up. There’s a good reason why Google remains at the forefront of the deep learning revolution: data, and lots of it.
By contrast, Apple is hamstrung by its own privacy policies. As an iPhone encrypts and holds data on the device itself, Apple has little in the way of user data to exploit. One former Apple employee told Reuters that Siri retains user data for six months, but Apple Maps user data can be gone in as little as 15 minutes. This pales in comparison to the amount of data that Google aggregates from Android users around the globe. Potentially, this disparity may stifle Apple advances in AI-driven technology, and especially where big data is essential to refine and perfect the learning process.
Not that Google has the AI research playing field all to itself. The Microsoft Deep Learning Technology Center would certainly argue it’s a big player, as its mission statement makes abundantly clear. “Our major goal is to build advanced deep learning technologies that empower all-seeing, all-knowing, and all-helping intelligent machines, and to work with our engineering-group partners to create the next big things”. Those “things” include the Deep Semantic Similarity Model (DSSM), which it’s putting to work in a variety of applications including web search ranking, contextual searching and advertising relevance.

Image: Microsoft DSSM architecture – simple stuff, really
Another player with access to large amounts of money and data is Facebook AI Research (FAIR) – Facebook hired one of the best known deep learning academics, New York University’s Professor Yann LeCun, to lead a team of more than 50 researchers. FAIR has already come up with a “memory network” that is able to answer basic common-sense questions, on subjects where it has never seen the text before. By feeding it a plot summary of Lord of the Rings, the network was able to then answer questions such as “where is the ring?”
Facebook founder Mark Zuckerberg has spoken about a new app for US users called Moments that is driven by deep learning-based image recognition systems. This, he says, also recognises which of your friends are in the photos you take and then lets you share them, but the potential is far greater. “Imagine a system that can identify words on a screen for a blind person and read them aloud, help an autistic child decipher facial expressions, or identify street signs in one language and instantly translate them to another”.
As easy as A, B, C
“Deep learning algorithms in the Google+ Image Search engine now recognise the subject in photos automatically.”
However, it’s Google that appears to be pulling ahead when it comes to applying the technology to everyday problems. By using deep learning processes for the server-based speech recognition in Android devices, Google has seen word accuracy jump from 77% to 92%. Deep learning algorithms within the Google+ Image Search engine now recognise the subject in photos automatically. However, despite an error rate of just 5% (which is as good as humans performing the same task), it does sometimes get things very wrong – there was the recent case where it mistakenly identified a black woman as a gorilla.
At the end of last year, Google announced that its latest system now had the ability to describe photos and images with detailed text captions. One of the images used by the Google Research team was of some pizza slices atop an old oven, which the algorithm correctly identified and captioned as “two pizzas sitting on top of a stove top oven.” The applications for such abilities stretch far beyond the ability to automatically sort photographs by keyword: this descriptive ability could be of huge help to visually impaired people navigating the web or, in tandem with a smartphone, it could effectively help the blind to “see”.

Image: Two pizzas sitting on top of a stove top oven
To the layperson, with little to no understanding of the programming complexity involved in such an achievement, it really cannot be over-emphasised how difficult it is for a computer to summarise a complex scene such as this – something that humans are capable of doing in a blink of the eye.
However, this is only the beginning. Google is using the lessons it’s learnt in image recognition to advance a whole gamut of technologies including speech recognition, Street View detection, language translation and spam detection.
Dude, where’s my car?
It’s not just search engines, photo albums and speech systems that are benefitting from deep learning – Google is also using the technology in its research and prototyping of self-driving vehicles. The idea is to enable these vehicles to perceive pedestrians in a similar way to us when we’re driving, to recognise automatically what poses a danger on the roads.
It’s a concept that is making slow, steady progress. Audi has unveiled an autonomous A7 (and more recently, the R8 E-Tron Piloted Driving) that uses a Nvidia processor to perform object recognition, and even specifics such as reading speed signs at the side of the road. Indeed, many of the advances in self-driving cars have involved deep learning algorithms to some degree.

Professor Nick Reed, academy director at the Transport Research Laboratory (TRL), agrees that deep learning is a very important tool, but one that raises serious concerns. “Deep learning is somewhat opaque. It can be hard to understand the rules or knowledge learnt by the system. In the case of self-driving cars, this may become important in the event of a collision. For example, if a vehicle is dependent on a deep learning algorithm, it may be difficult to understand how the vehicle used the available information to determine its actions, subsequently resulting in a lack of clarity over liability.”
Reed touches upon the gnawing legal and ethical issues at the heart of autonomous driving – issues that may potentially have wide-reaching implications for the application of deep learning systems in other fields. Once computers can make decisions that affect human lives, difficult questions need to be addressed.
It’s a truly awe-inspiring achievement to put a computer behind the wheel, but how much control can we knowingly cede to a computer that has no morals, no ethics, only programming. If an autonomous car kills, who do we blame?
Before deep learning sets its mind to driving, it’s questions such as these that will be the hardest to answer.
Related Posts
 What is Kodi? Everything You NEED to Know about The TV Streaming App
What is Kodi? Everything You NEED to Know about The TV Streaming App
 Minecraft Legends: Everything We Know
Minecraft Legends: Everything We Know
 How to Transfer Everything and Move to a New Email Account
How to Transfer Everything and Move to a New Email Account
 Here’s Why Everything is Green in Google Maps
Here’s Why Everything is Green in Google Maps
 How to Share Your Spotify Playlist
How to Share Your Spotify Playlist
 How to Check Your Instagram Messages
How to Check Your Instagram Messages
 How to See Recently Added Friends on Facebook
How to See Recently Added Friends on Facebook
 How to Leave a Group in Facebook Messenger
How to Leave a Group in Facebook Messenger
 How to View Recently Watched Videos on Facebook
How to View Recently Watched Videos on Facebook
Disclaimer: Some pages on this site may include an affiliate link. This does not effect our editorial in any way.


