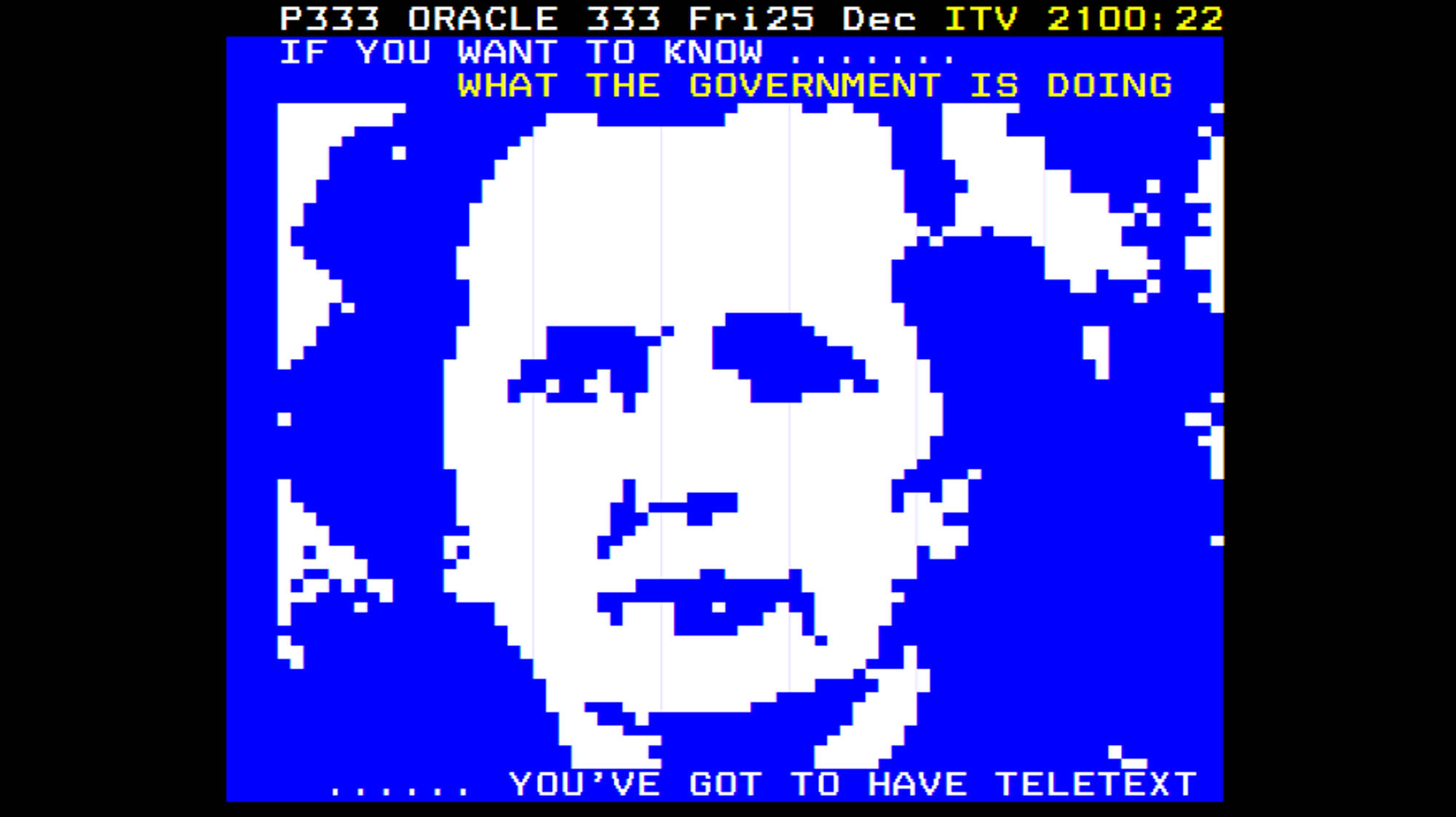
Long before the World Wide Web became the so-called “information superhighway”, we had teletext. By comparison, it was more of a dirt track. But the service was hugely important. The first teletext service, Ceefax, launched on BBC channels in 1974 and was quickly followed by a competing service (first ORACLE, then one simply called Teletext) on ITV and Channel 4.
“If you wanted the latest headlines or the football scores in the era before the internet, Teletext was the only option.”
News, weather, TV schedules and a wealth of other digital information was encoded into TV signals that could be accessed by hitting the “Text” button on TV remotes. To access the information you wanted, you had to simply dial in the number of the page you wanted using the remote control, and your cathode-ray tube would cycle through and wait for page to appear. It wasn’t quick, it wasn’t pretty, but if you wanted the latest headlines or the football scores in the era before rolling news or the internet, it was the only option.
By any measure, teletext was hugely successful and widely used. According to Teletext in Europe, in the early 1980s the average teletext user checked the service 77 times per week – spending nine minutes browsing every day. By the 1990s, 20 million were checking teletext services at least once per week – a bigger figure than many newspapers’ circulation figures.
Press Reveal
In the age of the internet, we take it for granted that we can tap in the name of almost any TV show in history and find footage of it within seconds. Similarly, if you wanted to find out what was on page 17 of The Times on 16 October 1981, even if it isn’t online we know that somewhere there is an archive with a paper copy gathering dust.
“Despite the system’s popularity, the archived pages appear to have almost disappeared without a trace.”
But what about teletext? At the time, broadcasters were required to keep everything they broadcast (including teletext) archived for 90 days for regulatory reasons – but despite the system’s popularity, the archived pages appear to have almost disappeared without a trace. Simply from the point of completeness, this glaring omission is frustrating from an archival and historical standpoint. How can it be that there is no remaining trace of a service that was relied on by 20 million people?
According to my numerous enquiries, as far as I can tell both Teletext Ltd and the BBC didn’t routinely keep every page produced. In many cases, it appears that when text pages were updated they were simply written into the system directly over the top of the previous page – so there wasn’t even a file system as we might understand it being used. The BBC, which you might expect to be more diligent about archiving than its commercial competitors, only contains a limited number of screenshots and other material in its archive – mostly from the early days of Ceefax, or the late 1990s when it must have been clear that time was running out for the technology.
And for the viewing public, the only real traces of this once-mighty beast remain in a relatively meagre number of screenshots and video captures of “Pages from Ceefax”, which used to be broadcast overnight when BBC One and BBC Two were not broadcasting.
Teletext is surely doomed to the same fate as the likes of early Doctor Who and Dad’s Army episodes: to be erased from history, forever.
TV Plus
But perhaps there is a solution, thanks to a handful of dedicated archaeologists who are hard at work digging through the digital dirt.
Surprisingly, the most obvious place to begin the search is on old videotapes. Teletext was transmitted using unused bandwidth in analogue TV signals, with the data encoded into hidden “lines” in the TV pictures. The problem is that VHS tapes are not well suited to storing this extra information: VHS stores images at lower quality than they were broadcast, meaning that the information stored has degraded – similar to how a “lossy” compressed file, such as a JPEG or MP3, don’t retain as much of the data as bitmap images or WAV music files.
Continues on page 2: What’s the ideal medium for storing teletext data? S-VHS, of course
Other tape formats were created that were better suited to storing teletext data, such as S-VHS in the late 1980s – but they never really took off like VHS. This means that even if it is easier to extract data from S-VHS, there is much less potential source material in the wild.
In 2011, coder Alistair Buxton found a pile of old VHS tapes in his attic, and having previously messed around with open-source DVR app MythTV, he started to wonder if he could extract teletext data from the dusty tapes.
“You can think of teletext like a barcode, but one pixel high – a series of black-and-white lines.”
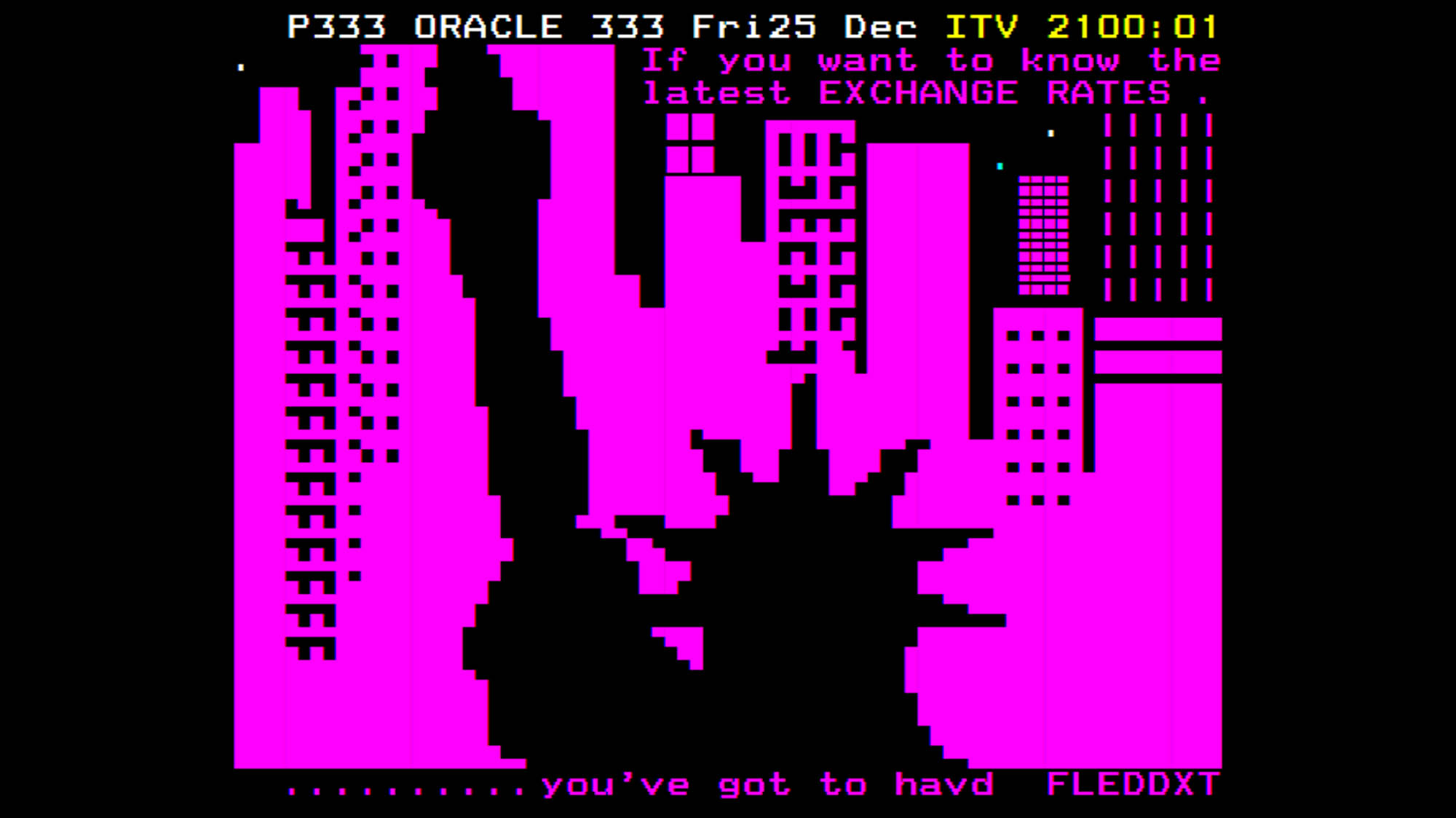
“You can think of teletext like a barcode, but one pixel high – a series of black-and-white lines,” Alistair told me. Unfortunately, it’s not stored on the tape quite so simply. “After I captured some, I could immediately see that it wasn’t just black or white any more. Instead of solid lines, everything was blurred together.”
It was at this point that Alistair had a moment of genius – and realised that separating the signal from the noise is exactly the problem that barcode readers in smartphones have when the camera isn’t focused correctly. So to clean up the captured data he was able to run it through a deblurring algorithm.

The resulting data was better – but there were still lots of errors and problems with the data. Because the deblurring algorithm has to make so many guesses, sometimes it guesses incorrectly – meaning that it could have picked out the wrong letters and so on.
So, how to mitigate this? Brilliantly, thanks to the way teletext works, there’s an almost built-in checking system: simply recording for longer.
Bamboozle
Teletext was encoded into the broadcasted TV signal, and under perfect circumstances you may need only five minutes of footage to capture every page, as five minutes should allow for inclusion of every sub-page on carousel pages. Those were the ones that had “(3/5)” in the corner, and which you’d have to wait for what felt like a lifetime for it to automatically switch to the next. The reason you had to wait – and the reason it was especially torturous if you were searching for a flight on a Teletext Holidays page with 70 subpages – is precisely because the data for each page was embedded in the live TV image and changed at regular intervals. When page one switched to page two, you’d have to wait for every single subpage to be broadcast in turn before you’d get back to page one.
But as we know, VHS recordings are of a much lower quality than the original broadcasts. And this is where a clever method of error correction comes in. Jason Robertson, another hobbyist who uses and has built upon Alistair’s software, tells me that he tends to capture 20-45 minutes’ worth of footage.

What this means is that when the data is slowly crunched through by his computer, each text page is captured a number of different times. And this enables for a form of error correction. Just as the last digit in the barcode is a check digit, making it possible to use mathematics to fill in any missing blanks, Alistair’s software compares the different versions of the semi-complete pages to fill in the blanks. For example – if two pages contain “CEEFAX” and one contains “CEEFAB” in the same place, it’s a safe bet that “CEEFAX” is the correct word.
To double-check this data, Jason has written his own teletext-editing software, and code that will generate a complete archive of the day’s pages in HTML, so you can go and relive the 23 October 1998 like you really were watching TV that day.
Fastext
Unfortunately, extracting text pages is hard work. Once the video has been captured from a tape, it takes about a day for a computer to crunch through a 5GB data file. But the future of teletext archaeology could be about to receive a massive speed boost.
Continues on page 3: Turning a Raspberry Pi into a teletext broadcaster
Brilliantly, Alistair Buxton has also created software that will turn a Raspberry Pi into a teletext broadcaster. Simply install the software with a few taps on the command line and plug the Pi into your TV using the old-fashioned RCA socket rather than HDMI. Then it’s just a case of hitting the teletext button on your TV remote to see a fully working teletext system, just as you remember it. This isn’t a simulation or a recreation using the Raspberry Pi’s graphics processor – this is teletext inserted into the TV signal in exactly the same way that it was back in the day.
This is fun for us laypeople, as Alistair has included vintage archive of teletext pages to browse with the software, but it also serves a smarter purpose for the archaeologists. Alistair has created a series of text pages with a very specific pattern, and used the Pi to record this to VHS.

Reading this data from a VHS back into his capturing system has enabled him to create a lookup table. This is essentially a teletext cheat sheet – he now has data on what many different combinations of teletext bytes might look like, rather than having to crunch and compare each byte manually with the original image algorithm, which makes the process of decoding much faster. At the moment, the new system is less accurate than the slow method, but brilliantly, it makes it possible to capture the teletext signal in “near real time”. This means no more waiting for a day to process a single set of pages.
Club 140
Browsing the data that Jason has captured and processed is a blast from the past. If you follow him on Twitter, you’ll see that he’s recently been bringing back from the dead pages of the much-loved Channel 4 video-game section, Digitiser – and has been able to share them with its writer, Paul “Mr Biffo” Rose, who has described Jason as a “legend” for his work.
At the moment, Jason and Alistair are pretty much the only real teletext archaeologists – although the wider teletext “scene” appears to encompass a few hundred people. Jason tells me he has ideas about making a proper archive, but this appears to be a way off yet.
At the moment, the best place to find what has been captured is on Jason’s blog.
Do you see?
Google’s Vint Cerf has warned that we risk a “forgotten century” as humans take their first footsteps into the digital world. He wasn’t talking about teletext, but something much bigger: the internet, of which he is credited as one of the founding fathers.
As fewer and fewer hard records are made of the vast amounts of information on the internet, there is a very real risk that historians of the future won’t have access to material that will help them understand how we lived and why we did the things that we did.
“The problems of archiving the web are much like the ones facing teletext, but on an even grander scale.”
And the problems of archiving the web are much like the ones facing teletext, but on an even grander scale. Just as teletext is locked away on old VHS tapes, much of our formative digital data is stored on formats we no longer use, such as floppy discs. And even if we could access the data, there are real worries about “bit rot” – as file formats change, and old applications give way to new, will we always be able to interpret the 0s and 1s? Sure, JPEGs might be ubiquitous today, but with the march of technology it is surely inevitable that they will be replaced. The billions of photos we have as a record of our lives today could in future become even more inaccessible than the noisy analogue TV signal on an old VHS cassette.
Ultimately, perhaps the work of Jason, Alistair and the other teletext archaeologists is not only valuable in its own terms – as they’re capturing historical data that would otherwise be lost – but could also serve as a warning: we need to be better at looking after our historical data, and we need to change before it is too late.
Disclaimer: Some pages on this site may include an affiliate link. This does not effect our editorial in any way.